
Lors du développement de logiciels, il est essentiel de garder à l’esprit que votre logiciel doit toujours évoluer. Il doit constamment être entretenu, amélioré avec de nouvelles fonctionnalités et corrections de bogues. Avec le temps, de nouveaux développeurs peuvent rejoindre ou quitter l’entreprise, ce qui peut rendre les choses difficiles à gérer et compliquer la maintenance du logiciel. Par conséquent, il est crucial de développer un logiciel maintenable, c’est-à-dire un logiciel qui pourra être facilement maintenu par les futurs développeurs.
Mais qu’est-ce qu’un logiciel maintenable?
C’est un logiciel que tout développeur devrait être en mesure d’améliorer et de corriger sans craindre de casser quelque chose sous le capot. Tout développeur, familier avec le domaine, devrait être en mesure de comprendre le code et de savoir facilement où apporter des modifications. La modification de la couche de présentation ne doit pas rompre la logique métier. La modification de la modélisation de la base de données ne doit pas affecter les règles métier du logiciel. Vous devriez être en mesure de tester facilement votre logique métier.
Ensuite, nous devrions commencer à réfléchir à la séparation des différentes préoccupations en différentes unités de code.
Qu’est-ce que l’architecture Oignon – Onion Architecture ?
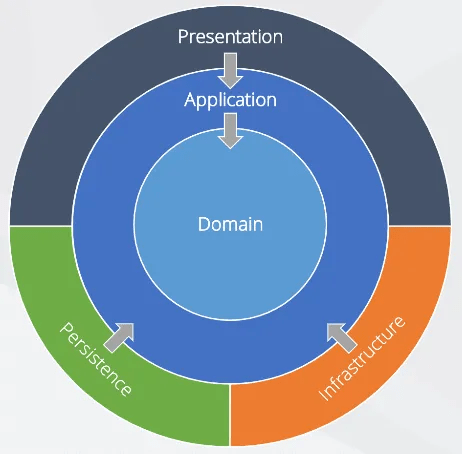
L’architecture Oignon – Onion Architecture est un modèle architectural qui propose que les logiciels soient créés en couches, chaque couche ayant sa propre préoccupation.
La règle d’or de l’architecture est que :
Rien dans un cercle intérieur ne peut savoir quoi que ce soit sur quelque chose dans un cercle extérieur. Cela inclut les fonctions, les classes, les variables ou toute autre entité logicielle nommée.
Robert C. Martin
Cette règle existe également dans d’autres architectures similaires, telles que l’architecture Clean.
Elle repose sur l’injection de dépendances pour réaliser l’abstraction des couches, afin que vous puissiez isoler vos règles métier de votre code d’infrastructure, comme les référentiels et les vues. En isolant votre logique de domaine, il devient facile à tester et plus facile à maintenir.
Elle a été proposée par Jeffrey Pallermo sur son site web.
Design Driven Domain (DDD)
Le Design Driven Domain (DDD) est le concept selon lequel les développeurs et les experts du domaine doivent utiliser les mêmes noms à la fois dans le code et dans le domaine commercial.
Le terme a été inventé par Eric Evans dans son livre Domain-driven Design: Tackling Complexity in the Heart of Software.

Ubiquitous language between domain experts and developers
Les noms liés au domaine tels que Marchandise, Navire, Utilisateur, etc., doivent avoir la même signification à la fois dans les règles du domaine et dans le code logiciel. Les développeurs de logiciels et les experts du domaine doivent être capables de parler dans un langage omniprésent et commun.
En utilisant les mêmes noms, la barrière linguistique entre les développeurs et les experts du domaine n’existera plus, et les nouvelles demandes telles que les fonctionnalités et les améliorations seront mieux comprises par les deux parties. Par conséquent, le développement se déroulera mieux et plus rapidement.
Domain Model
L’un des concepts clés de DDD est le modèle de domaine. Un modèle de domaine est une entité qui intègre le comportement et les données d’un modèle commercial.
En fait, dans un langage orienté objet, par exemple, il peut s’agir d’une classe qui contient des méthodes décrivant le comportement du modèle selon les règles de l’entreprise, ainsi que les données contenues dans le modèle.
Séparation des couches
L’architecture Ognon propose trois couches différentes :
- La couche Domaine
- La couche Application
- La couche Infrastructure
Couche Domaine
La couche de domaine est la couche la plus interne de l’architecture.
Les modèles de domaine et les services seront à l’intérieur de cette couche, contenant toutes les règles métier du logiciel. Il doit être purement logique, ne réalisant aucune opération d’entrée/sortie.
Comme cette couche est purement logique, il devrait être assez facile de la tester, car vous n’avez pas à vous soucier de la simulation des opérations d’entrée/sortie.
Cette couche ne peut pas non plus connaître quoi que ce soit déclaré dans les couches d’application ou d’infrastructure.
Les modèles de domaine – Domain Models
Les modèles de domaine sont au cœur de la couche de domaine. Ils représentent les modèles commerciaux, contenant les règles métier de leur domaine.
Un exemple d’un modèle de compte bancaire
import java.time.LocalDateTime;
import java.util.List;
public class Account {
private double amount;
private User owner;
private List<Transaction> transactions;
private LocalDateTime createdAt;
public double getAmount() {
return amount;
}
public void setAmount(double amount) {
this.amount = amount;
}
public User getOwner() {
return owner;
}
public void setOwner(User owner) {
this.owner = owner;
}
public List<Transaction> getTransactions() {
return transactions;
}
public void setTransactions(List<Transaction> transactions) {
this.transactions = transactions;
}
public LocalDateTime getCreatedAt() {
return createdAt;
}
public void setCreatedAt(LocalDateTime createdAt) {
this.createdAt = createdAt;
}
public void withdraw(double amount) {
// implementation
}
public void deposit(double amount) {
// implementation
}
public void getStatement(double amount) {
// implementation
}
}
Les services de domaine – Domain Services
Il y a des cas où il est difficile d’adapter un comportement à un modèle de domaine unique. Imaginez que vous modélisiez un système bancaire, où vous avez le modèle de domaine Compte. Ensuite, vous devez implémenter la fonctionnalité de transfert, qui implique deux comptes. Il n’est pas si clair que ce comportement doit être implémenté par le modèle de Compte, donc vous pouvez choisir de l’implémenter dans un service de domaine.
Un service de domaine contient un comportement qui n’est pas attaché à un modèle de domaine spécifique. Il pourrait être essentiellement une fonction, au lieu d’une méthode.
Notez qu’idéalement, vous devriez toujours essayer de mettre en œuvre des comportements dans des modèles de domaine pour éviter de tomber dans le piège du modèle de domaine anémique.
Les objets de valeur – Value Objects
Un objet de valeur est un objet qui n’a pas d’identité et qui est immuable. Ces objets n’ont pas de comportement, étant simplement des sacs de données utilisés aux côtés de vos modèles. Exemples :
- Un objet Adresse, qui représente un emplacement physique.
- Un objet Point, qui représente une coordonnée.
Vos modèles de domaine peuvent avoir des objets de valeur dans leurs attributs, mais l’inverse n’est pas autorisé.
public record Point(int x, int y) {}Un exemple simple d’objet de valeur
Couche Application
La couche application est la deuxième couche la plus interne de l’architecture.
Cette couche est responsable de la préparation de l’environnement pour vos modèles, afin qu’ils puissent exécuter leurs règles métier.
Elle implémente des règles d’application (parfois appelées cas d’utilisation) au lieu de règles métier.
Les règles d’application sont différentes des règles métier. Les premières sont des règles qui sont exécutées pour implémenter un cas d’utilisation de votre application. Les dernières sont des règles qui appartiennent à l’entreprise elle-même.
Exemple de règle d’application ou cas d’utilisation:
Charger un compte à partir d’un référentiel, appeler la méthode Account.Withdraw() en passant un montant, et envoyer le nouveau solde par e-mail au propriétaire du compte.
public void accountWithdraw(String accountID, double amount) {
// Il n'y a pas de gestion d'erreur pour simplifier le code
Account account = accountRepository.getAccount(accountID);
account.withdraw(amount);
accountRepository.saveAccount(account);
emailService.sendBalanceEmail(account);
}Exemple de règle métier :
Lorsqu’un retrait est demandé sur un compte, une taxe de 0,1 % doit être facturée.
public void withdraw(double amount) {
double deductions = amount + Taxes.WithdrawTaxes;
this.amount -= deductions;
}Voici un exemple de règle métier simple. Ainsi, pour ces exemples donnés, si les ordinateurs n’existaient pas, les règles métier seraient toujours appliquées. Les règles d’application ne le seraient pas. Cette règle de base peut généralement vous aider à distinguer ces différentes sortes de règles.
Notez que la couche d’application elle-même n’implémente aucune opération d’entrée/sortie. La seule couche qui implémente une E/S est la couche d’infrastructure. La couche d’application n’appelle que des méthodes d’objets qui implémentent les interfaces qu’elle attend, et ces objets (de la couche d’infrastructure) peuvent effectuer une E/S.
Services
Un Service d’Application est un morceau de code qui implémente un cas d’utilisation.
Il peut recevoir des objets qui implémentent certaines interfaces connues (injection de dépendance), et il est autorisé à importer des entités de la couche de domaine.
Interfaces
Si la couche d’application est censée coordonner des opérations qui impliquent une E/S, comme le chargement de données depuis un référentiel ou l’envoi d’un e-mail, elle doit déclarer certaines interfaces avec les méthodes qu’elle veut utiliser. Cette couche ne doit pas se soucier de la mise en œuvre de ces méthodes, mais simplement déclarer leurs signatures.
public interface AccountRepository {
Account GetById(String id) throws Exception;
Account GetByOwner(User owner) throws Exception;
void Save(Account account) throws Exception;
int Count() throws Exception;
double SumAllAmounts() throws Exception;
}Exemple d’interface
Data Transfert Object – DTO
Un objet de transfert de données (DTO) est un objet qui contient des données qui seront transférées entre différentes couches, dans un format spécifique.
Parfois, vous souhaitez transférer des données qui ne sont pas exactement un modèle de domaine ou un objet de valeur.
Par exemple, supposons que vous développiez un système bancaire. Vous implémentez ensuite un cas d’utilisation qui sert à l’utilisateur pour vérifier le solde de son compte.
Ainsi, le cas d’utilisation est le suivant :
- L’application reçoit une demande.
- Le compte de l’utilisateur est chargé depuis un référentiel.
- L’application renvoie un objet contenant le solde du compte, l’horodatage actuel, l’ID de la demande et quelques autres données mineures à des fins d’audit.
Disons que l’objet renvoyé ressemble à ceci :
import java.time.LocalDateTime;
public class AccountBalanceResponse {
private Account account;
private double balance;
private LocalDateTime timestamp;
private String requestId;
public AccountBalanceResponse(Account account, double balance, LocalDateTime timestamp, String requestId) {
this.account = account;
this.balance = balance;
this.timestamp = timestamp;
this.requestId = requestId;
}
public Account getAccount() {
return account;
}
public double getBalance() {
return balance;
}
public LocalDateTime getTimestamp() {
return timestamp;
}
public String getRequestId() {
return requestId;
}
}Cet objet n’a pas de comportement. Il contient simplement des données et est utilisé uniquement dans ce cas d’utilisation en tant que valeur de retour.
Cet objet peut être un DTO.
Les DTO sont bien adaptés en tant qu’objets avec des formats et des données très spécifiques.
En règle générale, vous ne devriez pas les implémenter dans le but de les réutiliser dans d’autres cas d’utilisation, car cela couplerait les deux différents cas d’utilisation.
Couche Infrastructure
La couche Infrastructure est la couche la plus externe de l’architecture en oignon. Elle est responsable de la mise en œuvre de toutes les opérations d’E/S requises pour le logiciel. Cette couche est également autorisée à connaître tout ce qui est contenu dans les couches internes, étant capable d’importer des entités des couches Application et Domain.
La couche Infrastructure ne doit pas implémenter de logique métier, ni de flux de cas d’utilisation.
Les référentiels, les API externes, les écouteurs d’événements et tout autre code qui traite les E/S de quelque manière que ce soit doivent être implémentés dans cette couche.
Référentiels – Repositories
Un référentiel est un modèle pour une collection d’objets de domaine. Il est responsable de la gestion de la persistance (comme une base de données) et agit comme une collection en mémoire d’objets de domaine.
En général, chaque agrégat de domaine a son propre référentiel (s’il doit être persisté), de sorte que vous pourriez avoir un référentiel pour les Comptes, un autre pour les Clients, et ainsi de suite. Par ailleurs, il n’est pas une bonne idée d’essayer d’utiliser un seul référentiel pour plus d’un agrégat, car vous pourriez finir par avoir un référentiel générique.
Dans l’architecture en oignon, la base de données n’est qu’un détail d’infrastructure. Le reste de votre code ne doit pas se soucier si vous stockez vos données dans une base de données, dans un fichier ou simplement en mémoire.
Vues (API, CLI, etc.)
Les parties de votre code qui exposent votre application au monde extérieur font également partie de la couche Infrastructure, car elles traitent les E/S.
Les couches internes ne devraient pas savoir si votre application est exposée via une API, via une CLI, ou autre.
Point d’entrée de l’application – injection de dépendance
Le point d’entrée de l’application (généralement, le main) devrait être responsable de l’instanciation de toutes les dépendances nécessaires et de leur injection dans votre code.
Si vous avez un référentiel qui attend un client PostgreSQL, le main devrait l’instancier et le passer au référentiel lors de son initialisation. C’est le mécanisme d’injection de dépendances.
import some.external.dependency.dbclient;
import myproject.application.services.BankingService;
import myproject.infrastructure.repositories.AccountRepository;
import myproject.infrastructure.views.api.API;
public class Main {
public static void main(String[] args) {
DbClient client = new DbClient();
AccountRepository repo = new AccountRepository(client);
BankingService svc = new BankingService(repo);
API api = new API(svc);
api.start();
}
}Exemple main()
Ainsi, le seul endroit de votre application qui crée réellement des objets capables de réaliser des E/S est le point d’entrée de l’application. La couche Infrastructure les utilise, mais ne les crée pas.
En faisant cela, votre code d’Infrastructure peut s’attendre à recevoir un objet qui implémente une interface, et le main peut créer les clients et les passer à l’infrastructure.
Ainsi, lorsque vous devez tester votre code d’infrastructure, vous pouvez créer une simulation qui implémente l’interface.
Avantages de cette architecture
Comme toute autre pattern, l’architecture en oignon – Onion Architecture a ses avantages et ses inconvénients.
Facilité de maintenance
Il est plus facile de maintenir une application qui a une bonne séparation des préoccupations. Vous pouvez modifier des éléments dans la couche d’infrastructure sans avoir à vous soucier de violer une règle métier. Il est facile de trouver où se trouvent les règles métier, les cas d’utilisation, le code qui traite la base de données, le code qui expose une API, et ainsi de suite.
De plus, le code est plus facile à tester grâce à l’injection de dépendances, ce qui contribue également à rendre le logiciel plus maintenable.
Indépendance vis-à-vis du langage et du framework
L’architecture en oignon ne dépend d’aucun langage ou framework spécifique. Vous pouvez l’implémenter dans pratiquement n’importe quel langage prenant en charge l’injection de dépendances.
Injection de dépendances partout! Facilité de test
En injectant les dépendances dans tout le code, tout devient plus facile à tester.
Au lieu de chaque module étant responsable de l’instanciation de ses propres dépendances, il a ses dépendances injectées lors de son initialisation. Ainsi, lorsque vous voulez le tester, vous pouvez simplement injecter un mock qui implémente l’interface que votre code attend.
Désavantages de cette architecture
Cependant, comme il n’y a pas de solution miracle, il y a quelques inconvénients.
Ne s’applique pas à tous types d’application
Lorsque vous n’avez pas beaucoup de règles métier Lorsque vous créez un logiciel qui ne traite pas de règles métier, cette architecture ne conviendra pas bien. Il serait vraiment fastidieux d’implémenter, par exemple, une simple passerelle en utilisant l’architecture en couches.
Cette architecture doit être utilisée lors de la création de services qui traitent des règles métier. Si ce n’est pas le cas, cela ne fera que perdre votre temps.

Courbe d’apprentissage
Il peut être difficile d’implémenter un service en utilisant l’architecture en couches lorsque vous avez une expérience centrée sur la base de données. Le changement de paradigme n’est pas si direct, donc vous devrez investir du temps dans l’apprentissage de l’architecture avant de pouvoir l’utiliser sans effort.
Pièges à éviter
Il y a certains pièges à éviter lorsque vous utilisez cette architecture.
Modèles de domaine anémiques
Si toutes vos règles métier sont dans les services de domaine au lieu d’être dans vos modèles de domaine, vous avez probablement un modèle de domaine anémique.
Un modèle de domaine anémique est un modèle de domaine qui n’a pas de comportement, juste des données. Il agit comme un simple sac de données, tandis que le comportement lui-même est implémenté dans un service. Ce modèle anti-pattern a beaucoup de problèmes qui sont bien décrits dans l’article de Fowler.
Notez que les modèles de domaine anémiques sont un anti-pattern lorsqu’on travaille avec des langages orientés objet, car lorsqu’on exécute une règle métier, on s’attend à changer l’état actuel d’un objet de domaine. Lorsqu’on travaille avec un langage de programmation fonctionnel, en raison de l’immutabilité, on s’attend à retourner un nouvel objet de domaine au lieu de modifier l’objet courant. Donc dans les langages fonctionnels, vos données et comportements ne sont pas étroitement couplés, et ce n’est pas une mauvaise chose. Mais bien sûr, vos règles métier doivent toujours être dans la bonne couche pour garantir une bonne séparation des préoccupations.
Commencer par modéliser la base de données
Lorsque vous travaillez avec Scrum, vous voudrez probablement découper le développement du logiciel en différentes tâches, afin qu’il puisse être réalisé par différentes personnes.
Naturellement, vous voudrez peut-être commencer le développement par la base de données, mais c’est une erreur! Lorsque vous travaillez avec Onion Architecture, vous devriez toujours commencer par développer les couches internes avant les couches externes. Donc, vous devriez commencer par modéliser votre couche de domaine, au lieu de la couche de base de données. Dans Onion, la base de données est juste un détail.
Il serait assez difficile de commencer par les dépôts, car :
- Les dépôts dépendent de la couche de domaine, car ils agissent comme une collection d’objets de domaine.
- Ils dépendent également des interfaces définies par la couche d’application, donc vous ne savez toujours pas quelles méthodes vous devrez implémenter.
Architectures similaires
Il existe d’autres architectures similaires qui utilisent certains des mêmes principes. Exemple :
- Clean Architecture
- Ports et adaptateurs, ou Architecture Hexagonale.


